读书笔记-算法-第五章
第五章 字符串
- Java字符串
- String是由一系列字符组成的。字符的类型是char,可能有个值。
- 不可变性。String对象是不可变的,因此可以将它们用于赋值语句、作为函数的参数或是返回值,而不用担心它们的值会发生变化
- 索引。我们最常完成的操作就是从某个字符串中提取一个特定的字符,即Java的String类的charAt()方法。我们希望charAt()方法能够在常数时间内完成,就好像字符串是保存在一个char[]数组中一样
- 长度。在Java中,String类型的length()方法实现了获取字符串的长度的操作。同样,我们也希望length()方法能够在常数时间内完成
- 子字符串。Java的substring()方法实现了提取特定的子字符串的操作。同样,我们也希望这个方法能够在常数时间内完成,Java的标准实现也做到了这一点
- 字符串的连接。在Java中通过将一个字符串追加到另一个字符串的末尾创建一个新字符串的操作是一个内置的操作(使用“+”运算符),所需的时间与结果字符串的长度成正比
- 我们会避免将字符一个一个地追加到字符串中,因为在Java里这个过程所需的时间将会是平方级别的
- 字母表
- 字母表的API
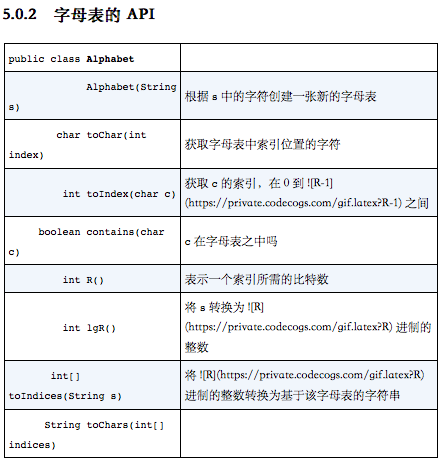
- 标准字母表

- 字母表的API
- 字符串排序
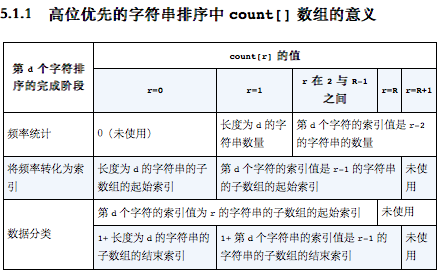
- 键索引计数法
- 频率统计
- 使用int数组count[]计算每个键出现的频率。
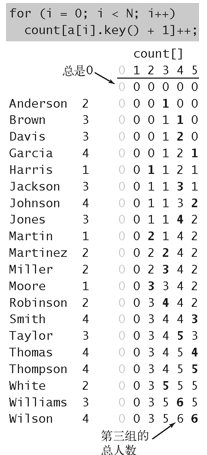
- 使用int数组count[]计算每个键出现的频率。
- 将频率转换为索引
- 使用count[]来计算每个键在排序结果中的起始索引位置

- 使用count[]来计算每个键在排序结果中的起始索引位置
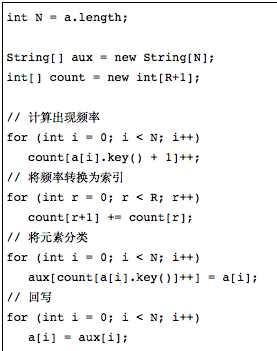
- 数据分类
- 将count[]数组转换为一张索引表之后,将所有元素(学生)移动到一个辅助数组aux[]中以进行排序
- 每个键都有起始位置,就是第二步获得的起始位置

- 回写
- 最后一步就是将排序的结果复制回原数组中
- 对于小整数键排序非常有效
- 键索引计数法排序N个键为0到R-1之间的整数的元素需要访问数组11N+4R+1次
- 突破了NlogN的排序算法时间下限
- 频率统计
- 低位优先(LeastSignificantDigitFirst,LSD)的字符串排序
- 适用于定长字符串,如车牌号,银行卡,身份证等
- 如果将一个字符串看作一个256进制的数字,那么从右向左检查字符串就等价于先检查数字的最低位
- 如果字符串的长度均为W,那就从右向左以每个位置的字符作为键,用键索引计数法将字符串排序W遍
- 从右向左排相当于最左边的位数最后排

- charAt(d) + 1 的作用是将任意字符转换为ASCII数字
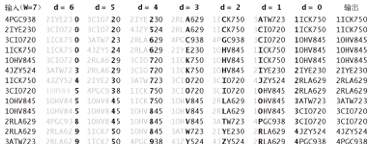
- 从右向左排相当于最左边的位数最后排
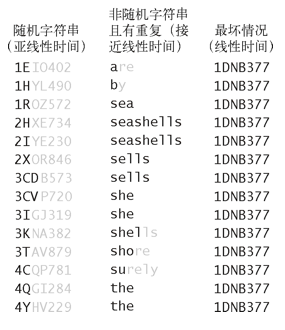
- 高位优先(MSD)的字符串排序,首先查看的是最高位的字符
- 针对非定长字符串的处理
- 具体实现
- 首先用键索引计数法将所有字符串按照首字母排序
- 然后(递归地)再将每个首字母所对应的子数组排序(忽略首字母,因为每一类中的所有字符串的首字母都是相同的)
- 增加了一个条件语句以在子数组较小时切换插入排序
- 小型子数组对于高位优先的字符串排序的性能至关重要
- 考虑不周的程序在从ASCII切换到Unicode后运行时间从几分钟暴涨到几个小时

- 对于含有大量等值键的子数组的排序会较慢
- 如果相同的子字符串出现得过多,切换排序方法条件将不会出现,那么递归方法就会检查所有相同键中的每一个字符
- 键索引计数法无法有效判断字符串中的字符是否全部相同
- 三向字符串快速排序
- 以根据高位优先的字符串排序算法改进快速排序,根据键的首字母进行三向切分,仅在中间子数组中的下一个字符(因为键的首字母都与切分字符相等)继续递归排序

- 三向字符串快速排序能够很好处理等值键、有较长公共前缀的键、取值范围较小的键和小数组——所有高位优先的字符串排序算法不擅长的各种情况
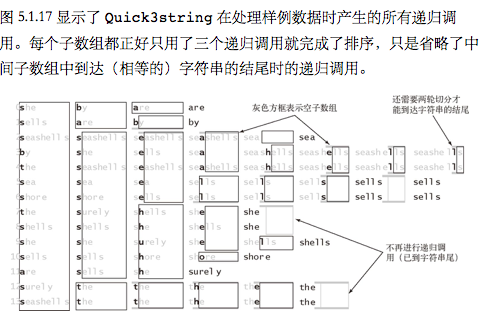
- 在所有的递归算法中,我们都可以通过对小型子数组进行特殊处理(一般来说就是切换为插入排序)来提高效率

- 性能
- 标准快速排序的性能与字符串的长度乘以2N*lnN成正比
- 三向字符串排序的运行时间则与N乘以字符串的长度(需要发现所有的相同开头字母)再加上2N*lnN次比较(对剩下的较短部分进行排序)的和成正比
- 以根据高位优先的字符串排序算法改进快速排序,根据键的首字母进行三向切分,仅在中间子数组中的下一个字符(因为键的首字母都与切分字符相等)继续递归排序
- 字符串排序算法的选择
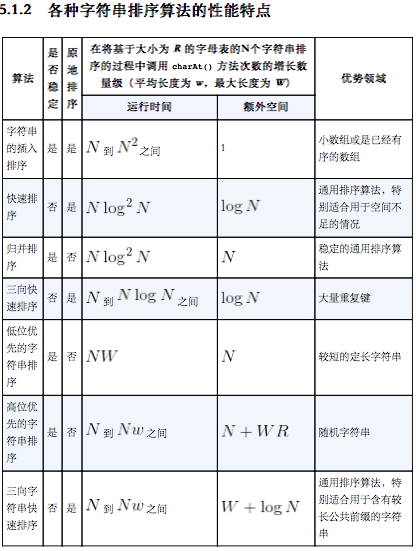
- 键索引计数法
- 单词查找树
- 定义
- 由字符串键中的所有字符构造而成,允许使用被查找键中的字符进行查找
- 和各种查找树一样,单词查找树也是由链接的结点所组成的数据结构,这些链接可能为空,也可能指向其他结点
- 每个结点都只可能有一个指向它的结点,称为它的父结点(只有一个结点除外,即根结点,没有任何结点指向根结点)
- 每个结点都含有条链接,其中为字母表的大小
- 值为空的结点在符号表中没有对应的键,它们的存在是为了简化单词查找树中的查找操作
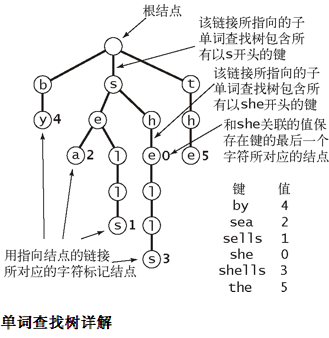
- 查找操作
- 单词查找树中的每个结点都包含了下一个可能出现的所有字符的链接,直到到达键的最后一个字母所指向的结点或是遇到了一条空链接。这时可能:
- 键的尾字符所对应的结点中的值非空(如图shells和she的示例)。这是一次命中的查找——键所对应的值就是键的尾字符所对应的结点中保存的值
- 键的尾字符所对应的结点中的值为空(如图shell的示例)。这是一次未命中的查找——符号表中不存在被查找的键
- 查找结束于一条空链接(如图shore的示例)。这也是一次未命中的查找
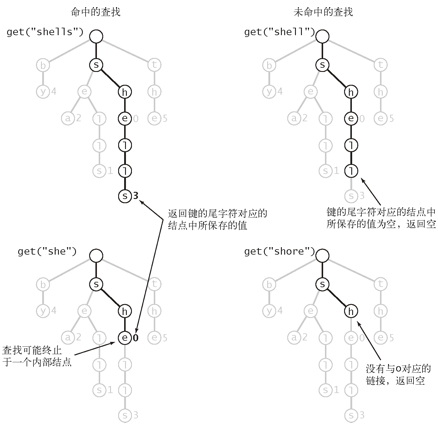
- 插入操作
- 在插入之前进行一次查找,如前文所述,可能遇到以字母结点为结尾或者空链接为结尾
- 在到达键的尾字符之前就遇到了一个空链接
- 在这种情况下,单词查找树中不存在与键的尾字符对应的结点
- 因此需要为键中还未被检查的每个字符创建一个对应的结点并将键的值保存到最后一个字符的结点中
- 在遇到空链接之前就到达了键的尾字符
- 在这种情况下,和关联数组一样,将该结点的值设为键所对应的值(无论该值是否为空)
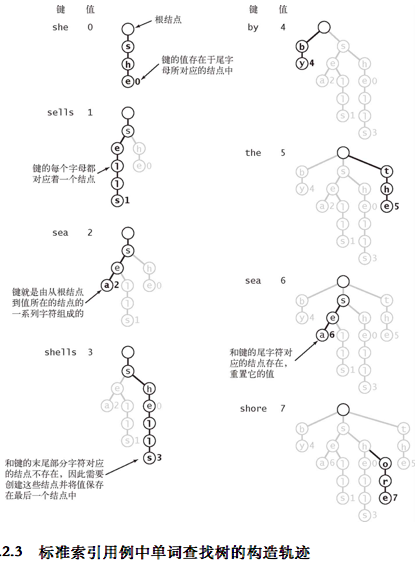
- 在这种情况下,和关联数组一样,将该结点的值设为键所对应的值(无论该值是否为空)
- 在到达键的尾字符之前就遇到了一个空链接
- 在插入之前进行一次查找,如前文所述,可能遇到以字母结点为结尾或者空链接为结尾
- 结点的表示
- 每个结点都含有R个链接,对应着每个可能出现的字符
- 字符和键均隐式地保存在数据结构中
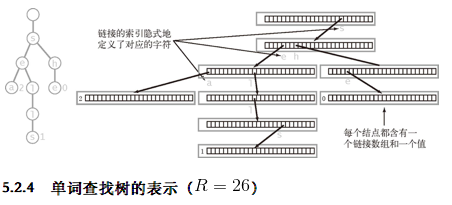
- 定义