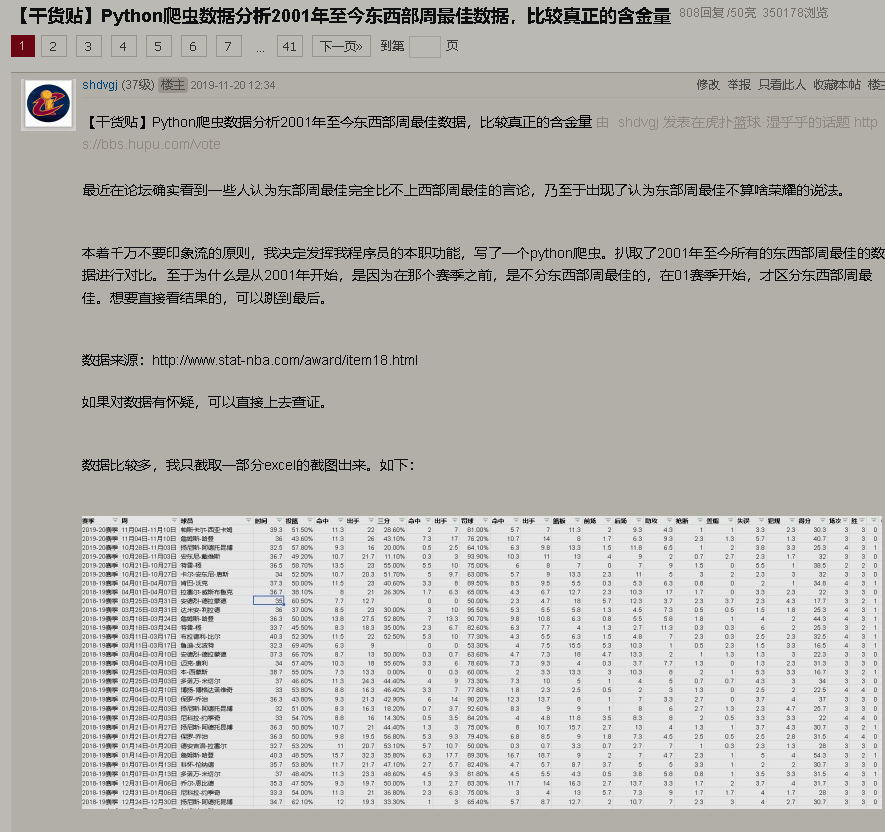
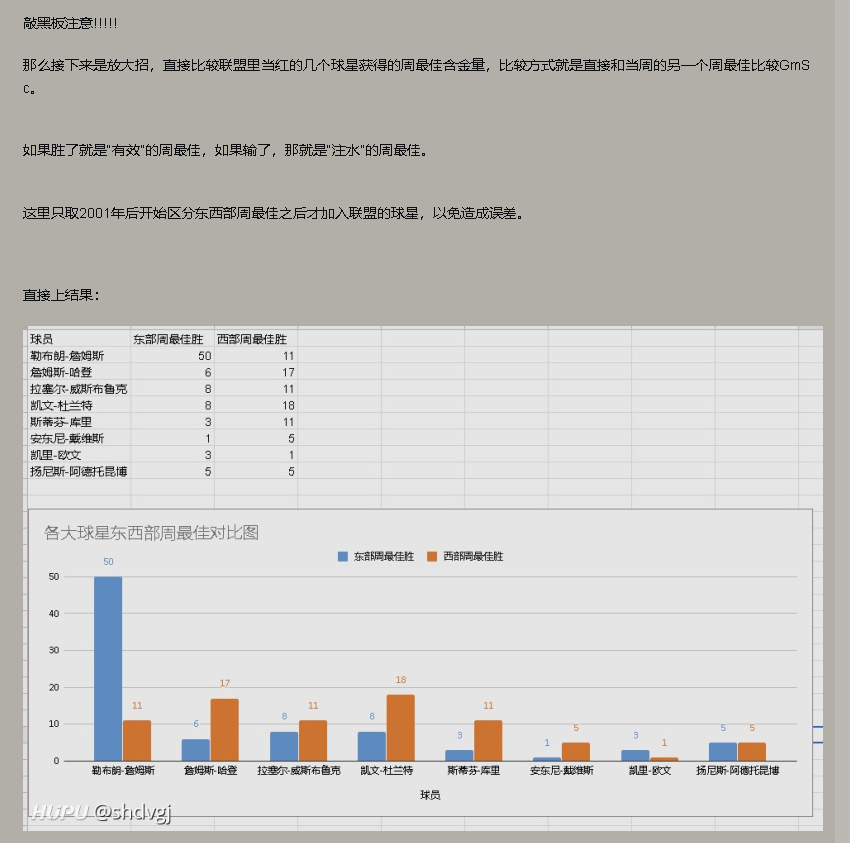
数据来源
历年周最佳的数据来自于NBA数据官网,链接为 http://www.stat-nba.com/award/item18.html

这里可以看到每个赛季的周最佳球员。然后每个球员旁边有个数据的链接,表示的就是这名球员当周的平均数据。比如11月11日-11月17日的东部周最佳是武切维奇,其数据链接为http://www.stat-nba.com/player/3672.html

数据处理
爬取周最佳球员
首先看周最佳的页面,链接是http://www.stat-nba.com/award/item18.html,选中武切维奇的名字,右键打开右键菜单,选择“查看页面元素”。出现如下页面:
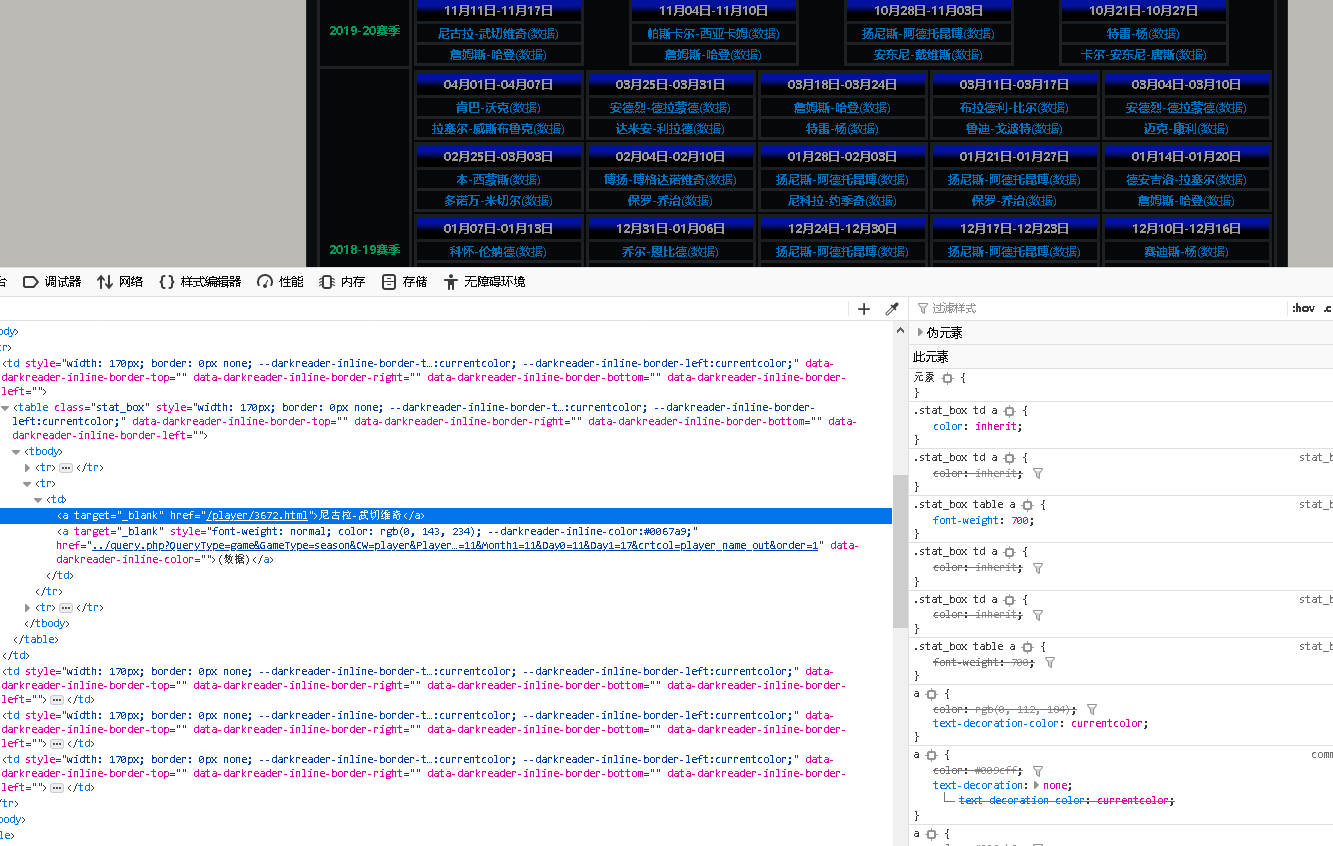
注意,我们需要获取到的是所有的周最佳数据,而不是某个人的,因此我们需要找到这个页面元素的父元素,因此才能找到这个父元素下面的所有子元素-即所有的周最佳数据。
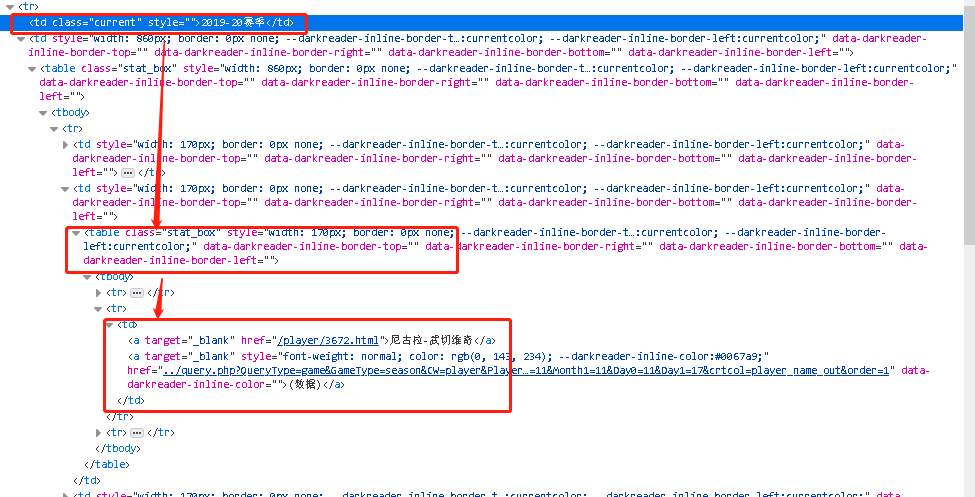
1
2
3
| 如图所示,周最佳数据的节点来自于<td class='current'> -> <table class='stat-box' style='width:170px;border:0'> -> <td>
根据网页上下文的查看,可以知道"<td class="current">是赛季的节点,<table class="stat-box" style="width:170px;border:0">是每个赛季下每周的节点,而<td>就是每周下面每个球员的节点。
|
因此我们根据节点的继承关系,可以写出如下的基本的爬虫逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.stat-nba.com/award/item18.html").read().decode('utf-8')
soup = BeautifulSoup(html, features='lxml')
outResult = soup.find_all("td", {"class": "current"})
for i in range(len(outResult)):
single = outResult[i]
data = single.parent.find_all("table", {"class": "stat_box", "style": "width:170px;border:0"})
for j in range(len(data)):
singleData = data[j]
week = singleData.find("th")
tdList = singleData.find_all("td")
for k in range(len(tdList)):
singleTd = tdList[k]
print(week.text, singleTd.text)
|
输出结果如下:
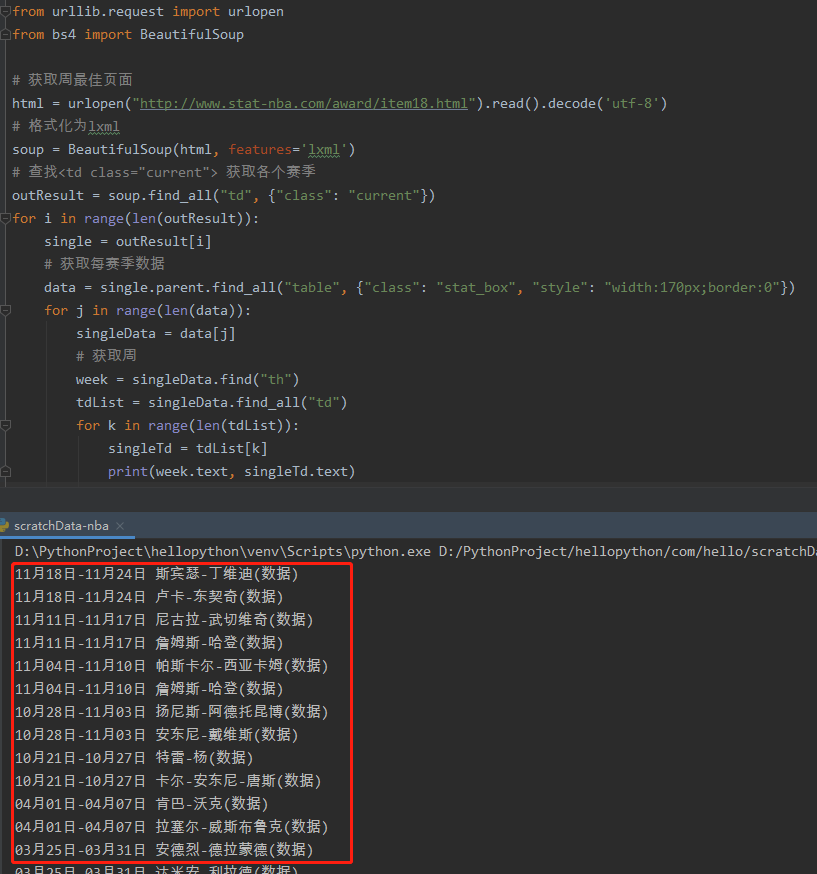
爬取周最佳数据
接下来我们爬取每个球员的周最佳数据,点击球员旁边的“数据”按钮,会跳转到周数据页面。
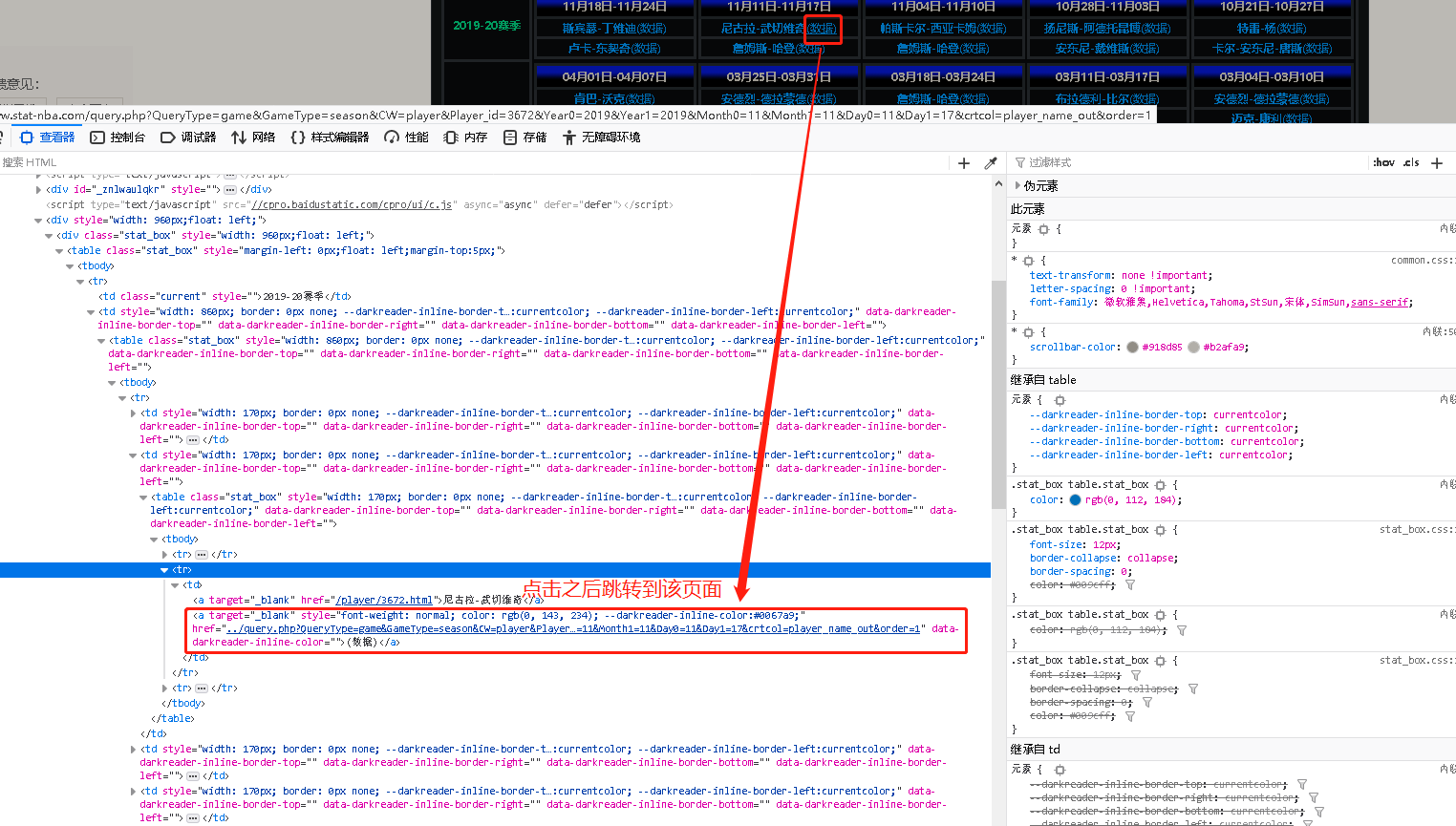
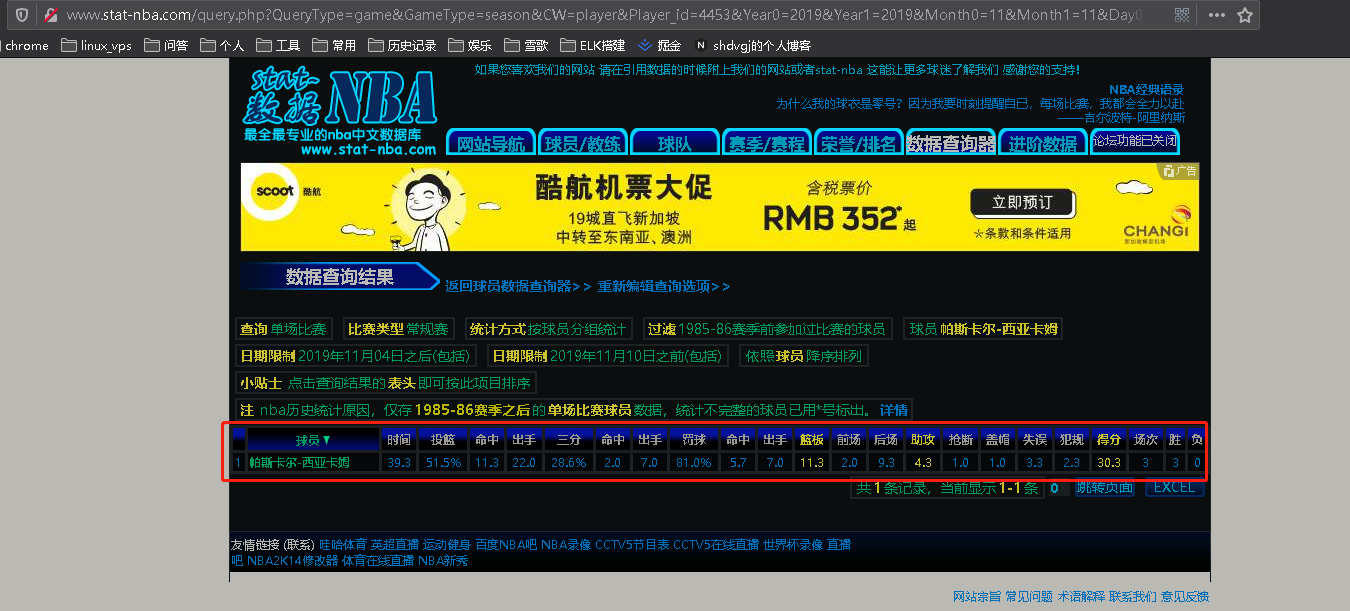
根据看到数据页面是在球员td标签下的第二个a标签下

根据a标签的结构使用如下代码来获取球员数据的链接:
1
2
3
4
| tdData = singleTd.find_all("a")
if len(tdData) > 1:
playerUrl = tdData[1].attrs['href'].replace("..", "http://www.stat-nba.com", 1)
|
获取到链接之后,按照前文所述来爬取球员的详细数据:
1
2
3
4
5
6
7
8
9
10
11
12
|
playerUrl = tdData[1].attrs['href'].replace("..", "http://www.stat-nba.com", 1)
playerHtml = urlopen(playerUrl).read().decode('utf-8')
playerSoup = BeautifulSoup(playerHtml, features='lxml')
playerTable = playerSoup.find("table", {"class": "stat_box"})
if hasattr(playerTable, 'find_all'):
playerStatList = playerTable.find_all("td")
if hasattr(playerTable, 'find_all'):
for m in range(1, len(playerStatList)):
playerStat = playerStatList[m]
print(playerStat.text)
|
输出数据到Excel
将前文进行整合,并将数据输出到Excel,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| import random
import time
from urllib.request import urlopen
import xlwt as xlwt
from bs4 import BeautifulSoup
def set_style(name='Times New Roman', height=220, bold=False):
style = xlwt.XFStyle()
font = xlwt.Font()
font.name = name
font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style
html = urlopen("http://www.stat-nba.com/award/item18.html").read().decode('utf-8')
soup = BeautifulSoup(html, features='lxml')
outResult = soup.find_all("td", {"class": "current"})
f = xlwt.Workbook()
sheet1 = f.add_sheet('周最佳数据', cell_overwrite_ok=True)
num = 0
style = set_style()
for i in range(len(outResult)):
single = outResult[i]
if single.text.startswith("19"):
break
data = single.parent.find_all("table", {"class": "stat_box", "style": "width:170px;border:0"})
for j in range(len(data)):
singleData = data[j]
week = singleData.find("th")
tdList = singleData.find_all("td")
for k in range(len(tdList)):
singleTd = tdList[k]
sleeptime = random.randint(0, 1000)
time.sleep(sleeptime / 1000)
tdData = singleTd.find_all("a")
playerName = tdData[0].text
print(single.text, week.text, playerName)
if len(tdData) > 1:
playerUrl = tdData[1].attrs['href'].replace("..", "http://www.stat-nba.com", 1)
playerHtml = urlopen(playerUrl).read().decode('utf-8')
playerSoup = BeautifulSoup(playerHtml, features='lxml')
playerTable = playerSoup.find("table", {"class": "stat_box"})
if hasattr(playerTable, 'find_all'):
playerStatList = playerTable.find_all("td")
sheet1.write(num, 0, single.text, style)
sheet1.write(num, 1, week.text, style)
if hasattr(playerTable, 'find_all'):
for m in range(1, len(playerStatList)):
playerStat = playerStatList[m]
sheet1.write(num, 1 + m, playerStat.text, style)
num = num + 1
f.save('nbastat-week.xls')
|
输出的结果如下:
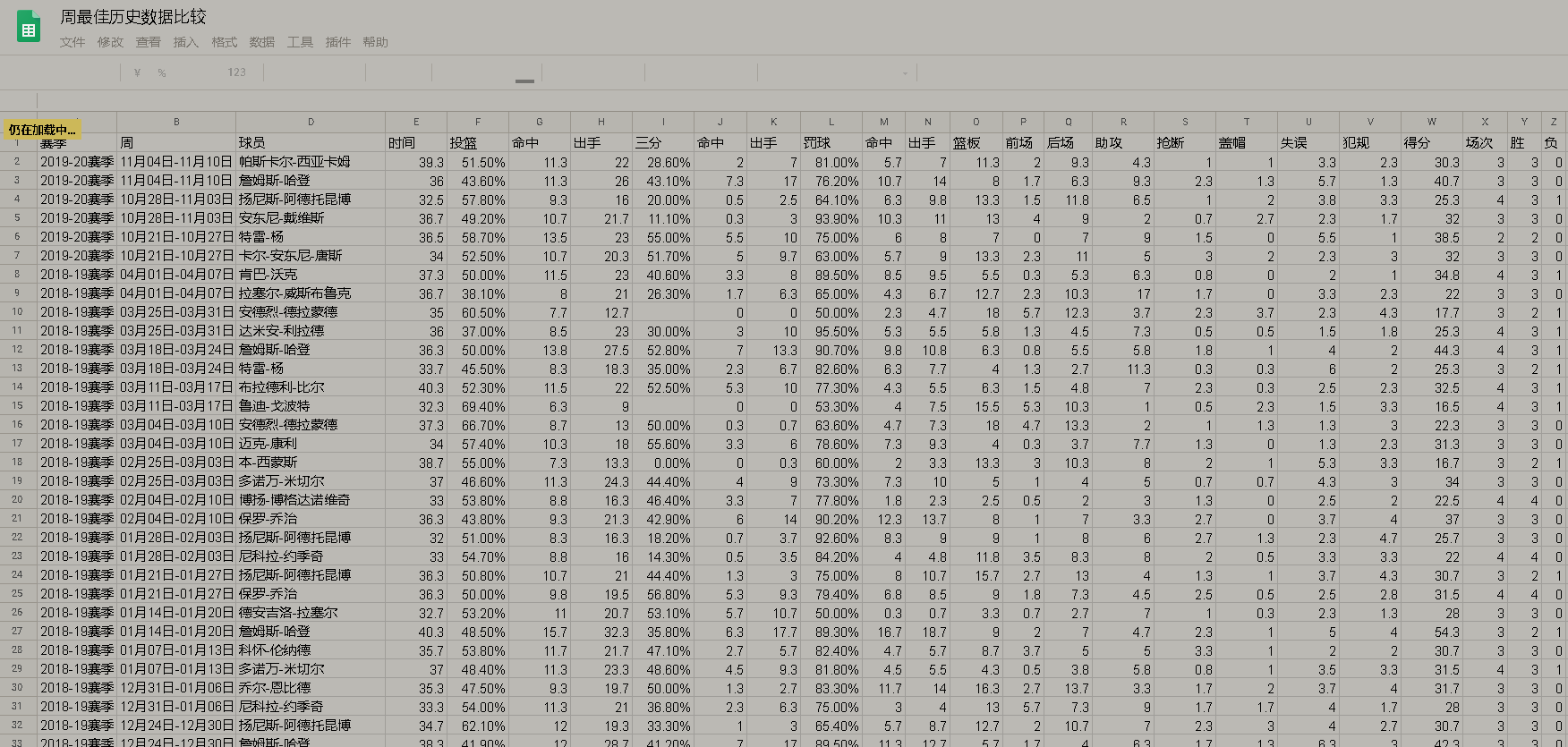
分析数据
分析过程我就懒得再写一遍了,之前已经将分析结果发布到虎扑,链接是https://bbs.hupu.com/30738461.html